7.5 Sistemas basados en reglas, tablas de decisión, y árboles de decisión en monitorización de estado y clasificación de situaciones, control y apoyo de decisiones
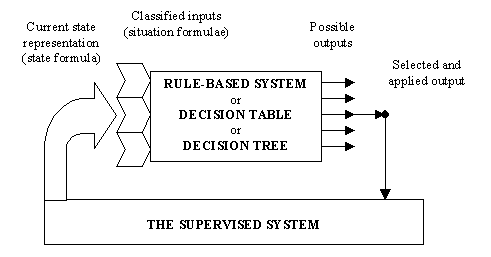
El esquema básico de funcionamiento es el mismo para todas las herramientas discutidas. A continuación se presentarán algunos problemas particulares acerca de la realización y aplicación. Se empezará con reconocimiento de situaciones o valoración de situaciones que son el mecanismo básico que verifica si y qué condiciones previas de la regla, tabla de decisión parte condicional o reconocimiento de sucesión de árbol de decisión se cumplen.
Reconocimiento de situaciones
También es posible usar una combinación de formalismos de representación del conocimiento - en este caso, las fórmulas que representan la información total deben estar compuestas de partes separadas expresadas mediante un solo formalismo. Para simplificar el tratamiento se asume que sólo ha sido escogido un formalismo. La extensión al uso simultáneo de varios formalismos (lenguajes de representación de conocimiento) es directa.
La suposición básica es que el estado del sistema se monitoriza,
y se construye una fórmula que describe estado actual en ciertos
intervalos de tiempo mediante la aplicación apropiada de algún
enfoque de la transformación señal-símbolo. Esta fórmula
-![]() - guarda la información
sobre el estado actual, es decir, parámetros de sistema, relaciones
que se mantienen, etc., para un intervalo de tiempo, a veces llamado ventana
de tiempo. De hecho, no es necesario escribir la fórmula explícitamente,
ciertos componentes simplemente deben ser accesibles si es necesario.
- guarda la información
sobre el estado actual, es decir, parámetros de sistema, relaciones
que se mantienen, etc., para un intervalo de tiempo, a veces llamado ventana
de tiempo. De hecho, no es necesario escribir la fórmula explícitamente,
ciertos componentes simplemente deben ser accesibles si es necesario.
Ahora supongamos que para la identificación de situaciones específicas
esperadas (condiciones previas, fallos, etc.) del sistema considerado se
ha determinado un conjunto de fórmulas que las define (y simultáneamente
describe). Sea ![]() un conjunto
de fórmulas de situación que define las posibles situaciones
de interés ,
un conjunto
de fórmulas de situación que define las posibles situaciones
de interés , ![]() ,
donde cada
,
donde cada ![]() es una fórmula
de situación que define cierto tipo de situación. El problema
de identificar la situación específica definido por la fórmula
es una fórmula
de situación que define cierto tipo de situación. El problema
de identificar la situación específica definido por la fórmula ![]() puede ser reemplazado ahora por verificar si esta fórmula generaliza
una fórmula
puede ser reemplazado ahora por verificar si esta fórmula generaliza
una fórmula ![]() que
describa el estado actual, si
que
describa el estado actual, si![]() .
.
Como los métodos para la comprobación de generalización
entre fórmulas ya se han presentado, el único problema restante
es evaluar todas las fórmulas de situación sistemáticamente
con respecto a la descripción de estado actual. Si ![]() se sostiene para alguna generalización, entonces la situación
específica definida por
se sostiene para alguna generalización, entonces la situación
específica definida por ![]() se confirma. Puede haber ocurrencia simultánea de varias situaciones
específicas (por ejemplo pueden satisfacerse condiciones previas
de varias reglas simultáneamente u ocurrir fallos múltiples)
al mismo tiempo.
se confirma. Puede haber ocurrencia simultánea de varias situaciones
específicas (por ejemplo pueden satisfacerse condiciones previas
de varias reglas simultáneamente u ocurrir fallos múltiples)
al mismo tiempo.
Problemas de aplicación práctica: una visión general
Destaquemos que la mayoría de las características
anteriores están, de una u otra manera, representadas y usadas en
cualquier sistema de control y supervisión basado en conocimiento.
En [Laffey et al, 1988] se
describen aproximadamente cincuenta aplicaciones diferentes, desde sistemas
aeronáuticos y espaciales hasta aplicaciones financieras, médicas,
en comunicaciones y de control automático, incluso aplicaciones
en robótica y en vehículos autónomos. Uno de los ejemplos
más llamativos consiste en un sistema experto en tiempo real que
controla a un robot jugador de tenis de mesa.
También se han descrito varias aplicaciones en dominios más clásicos del control automático. En algún articulo recopilatorio se describen aplicaciones de sistemas basado en conocimiento a la supervisión, diagnóstico, y control en el dominio de la automática [Tzafestas, 1987], [Tzafestas, 1989], [Tzafestas, 1989a]. Las aplicaciones de ejemplo incluyen autosintonía de controladores PID, un supervisor basado en reglas autosintonizado, un sistema experto para control de destilación, y supervisión experta de un motor turbo-diesel.
Problemas técnicos seleccionados
Para los problemas anteriores no puede proporcionarse una teoría
general y las soluciones prácticas dependen del problema específico.
Es más, la clasificación anterior se refiere a una estructura
de sistema de supervisión producto, en gran parte, de una convención.
De hecho, todos los problemas están fuertemente interconectados
y la selección de una solución a ciertos problemas en uno
de los grupos indicados puede proyectarse e influir en las soluciones de
otros problemas en otros grupos. Entre las áreas de influencia mutua
pueden distinguirse dos de gran importancia. En primer lugar, los problemas
en la entrada y la salida están entrelazados con los de representación
de conocimiento, y segundo, los problemas de representación de conocimiento
influyen en los problemas de razonamiento.
Los problemas en la entrada y en la salida son en cierto grado similares, ya que ambos involucran la interfaz entre el sistema de supervisión basado en conocimiento y el exterior. Las soluciones prácticas dependen del carácter de las señales (eléctricas, mecánicas, químicas, biológicas, etc.), posibilidades de adquisición (descubrimiento, medida, observación, etc.), la posibilidad de realizar acciones de control, sensores y actuadores accesibles, exactitud requerida, etc., Las soluciones prácticas pueden incluir la aplicación de gran variedad de instrumentos usados en el control automático clásico y no clásico, incluso cámaras y sistemas de procesado e interpretación de imágenes para la entrada, así como robótica o sistemas de manipulación capaces de realizar operaciones mecánicas complejas para la salida.
Los problemas de representación de conocimiento se interconectan fuertemente con los problemas de razonamiento. El problema básico de representación de conocimiento involucra la representación práctica de fórmulas de estado. La introducción teórica y la presentación en los capítulo 4 y 6 proporcionan sólo un planteamiento general que debe ajustarse a cualquier caso específico.
Tipos de hechos y su representación
Con respecto a la clasificación anterior de hechos, sólo
deben representarse necesariamente de forma explícita en la base
de conocimiento aquellos que pertenecen a los dos primeros grupos. Puede
ser poco razonable guardar los hechos de entrada y los de usuario en la
memoria, ya que, en cualquier instante, si son necesarios, pueden ser "leídos"
de la interfaz de entrada y el usuario puede simplemente pedirlos. Finalmente,
pueden generarse hechos deducibles, matemáticos, y específicos
del dominio según las necesidades actuales mediante el uso de mecanismos
de inferencia especiales, y probablemente esto sería más
eficaz que guardarlos en todo momento en la base de conocimiento. La utilización
este esquema de representación del conocimiento parcialmente implícito
puede contribuir significativamente a reducir la cantidad memoria requerida
para la representación del estado. Simultáneamente, puede
acelerar la ejecución, ya que la generación de ciertos hechos
puede ser más rápida que su búsqueda en una base de
conocimiento grande y el tiempo requerido para la actualización
de la base de conocimiento se reduce significativamente. Sin embargo, el
conocimiento implícito provoca problemas adicionales al mecanismo
de razonamiento y, particularmente, a los procedimientos de emparejamiento.
Si algunos hechos se representan implícitamente, los emparejamientos
directos de hechos incluidos en alguna fórmula simple (posiblemente
describiendo las condiciones previas de alguna regla de transformación)
con la fórmula de estado no son satisfactorios. Se requieren procedimientos
especializados de emparejamiento que cubran la generación de hechos
implícitos. En el general, debe tenerse en cuenta el equilibrio
entre las representaciones de conocimiento explícitas e implícitas,
deben considerarse varios factores. Por consideraciones prácticas,
se han seleccionado los siguientes tipos de hechos:
Como ejemplo, se muestra cómo los hechos anteriores se codifican
como términos de algunos meta-hechos que son cláusulas
de Prolog. Cualquiera de estos hechos puede tener varios argumentos aparte
del término que codifica la fórmula lógica; para el
ejemplo de aplicación se han escogido tres argumentos: el tipo de
hecho lógico, el átomo, es decir, la fórmula lógica
apropiada, y su valor de verdad actual. El siguiente extracto de programa
en Prolog muestra la estructura apropiada.
{ *** Types of facts *** }
{
state - specified by the state formula
control - special facts specifying state of the controller
memory
user - specified by the user
input - to be read as input data
infer - fact to be inferred according to given rules
special - interpreted according to special rules
The form of any fact in database is:
fact(<type>,<atom>,<truth-value>).
and f(<type>,<atom>) for preconditions,
where:
<type> = one of the above types,
<atom> = specification of the atomic formula defining the
fact,
<truth_value> = current status; true/false.
}
Para resumir, no puede esperarse una sola solución universal que proporcione un acercamiento consistente a la resolución de problemas de aplicación prácticos. En esta sección sólo se han esbozado agrandes rasgos los más obvios. Las siguientes subsecciones se dedican al análisis de ciertos problemas particulares poniendo por delante algunas pautas prácticas. Algunas de las consideraciones se apoyan en ejemplos simples de aplicaciones prácticas.
El mecanismo de control del razonamiento y el uso de heurísticas del dominio
El esquema anterior esboza el algoritmo básico de razonamiento
en un sistema del control basado en conocimiento. Las modificaciones principales
incorporadas en aplicaciones prácticas pueden involucrar los siguientes
problemas:
La segmentación de la base de reglas es un paradigma normalmente
usado en varios sistemas basados en conocimiento. El objetivo principal
de esta segmentación es reducir el número de reglas considerado
al mismo tiempo mediante la separación temporal de las reglas que
no son aplicables. La clave para seleccionar las reglas es el contexto
en curso. En sistemas del control el contexto puede definirse con respecto
al modo de funcionamiento, como por ejemplo automático, semiautomático,
manual, etc., Otro factor usado para determinar el contexto puede tener
en cuenta el status de funcionamiento por ejemplo funcionamiento normal,
arrancada, paro, emergencia, fallo, diagnóstico, etc. Dentro de
un contexto es posible distinguir varios subcontextos, y así realizar
más segmentaciones. Así se introduce una jerarquía
natural en el conjunto de reglas. El mecanismo de control de razonamiento
también trabaja entonces de forma jerárquica, primero determina
el contexto apropiado (y, posiblemente, el subcontexto), y luego realiza
la búsqueda normal teniendo en cuenta sólo el conjunto determinado
de reglas limitado al contexto. Este enfoque proporciona la posibilidad
de acelerar la ejecución, pero también es importante para
hacer la base de reglas mucho más transparente al usuario, más
fácil entender, dirigir, modificar y poner a punto.
Los mecanismos de resolución de conflictos están basados
normalmente en algunas suposiciones arbitrarias (como que el orden de las
reglas indica la jerarquía de ejecución; este enfoque constituye
uno de los principios del lenguaje de programación Prolog), o en
reglas heurísticas, por ejemplo asignando prioridades numéricas
a las reglas. En el general, los mecanismos más típicos de
resolución de conflictos operan siguiendo los siguientes principios:
Por supuesto, un sistema realista puede combinar los enfoques anteriores
e incluir algún otro. Sin embargo, no puede sugerirse ninguna solución
general, puesto que el diseño y aplicación de control del
razonamiento es una tarea altamente especializada y específica del
dominio.
Como ilustración, la estrategia básica llevada a cabo es una búsqueda lineal de reglas con ejecución de la primera regla encontrada; después de la ejecución de la regla se repite el ciclo de búsqueda. El orden de especificación de las reglas es equivalente a establecer prioridades, la primera regla tiene la prioridad más alta, etc. La aplicación más simple puede ser:
run:-
repeat,
findrule(_Number),
executerule(_Number),
test,!.
findrule(_Number):-
rule(_Number,_,_Preconditions,_,_,_),
consistent(_Preconditions),!.
executerule(_Number):-
rule(_Number,_,_Preconditions,_,_Dels,_Adds),
consistent(_Preconditions),
remove(_Dels),
add(_Adds).
test:-
rule(1,_,_Preconditions,_,_,_),
consistent(_Preconditions).
remove([]):- !.
remove([_F|_T]):- retract(fact(_F)),remove(_T).
add([]):- !.
add([_F|_T]):- assert(fact(_F)),add(_T).
La versión más simple de un intérprete de reglas como el presentado utiliza un formato simplificado de reglas y la prueba más simple para las condiciones previas. Otra versión de intérprete de reglas para búsqueda lineal y ejecución de la primera regla encontrada es:
run:-
write('LOOP'),nl,
findrule(_Number,_Name,_Preconditions,_Negative_preconditions),
executerule(_Number,_Name,_Preconditions,_Negative_preconditions),
!,
run.
run:-
nl,nl,nl, write('No rule applicable; operation halted').
findrule(_Number,_Name,_Preconditions,_Negative_preconditions):-
rule(_Number,_Name,_,_Preconditions,_Negative_preconditions,_,_,_,_,_),
write('Find rule: testing preconditions: '), write(_Number),nl,
satisfied(_Preconditions),
unsatisfied(_Negative_preconditions).
executerule(_Number,_Name,_Preconditions,_Negative_preconditions):-
rule(_Number,_Name,_,_Preconditions,_Negative_preconditions,
_Action,_Delete_results,_Add_results,_Message,_Next_rules),
write('Exec rule: No testing of preconditions: '), write(_Number),nl,
{satisfied(_Preconditions),
unsatisfied(_Negative_preconditions), }
write('Action executed: '),write(_Action),nl,
remove(_Delete_results),
add(_Add_results),
write(' *** INFO *** '),nl,write(_Message),nl.
remove([]):- !.
remove([f(_Type,_Term)|_T]):-
retract(fact(_Type,_Term,_)),remove(_T).
add([]):- !.
add([f(_Type,_Term)|_T]):-
write(_Type),write(' '), write(_Term),nl,
process(f(_Type,_Term),f(_Type,_New_term)),
write(f(_Type,_New_term)),nl,
assert(fact(_Type,_New_term,true)),add(_T).
process(f(state,angle(plus(_Angle,_Alpha))),f(state,angle(_New_angle))):-
data(_Alpha,_Given),
write(_Given),nl,
_New_angle is _Angle + _Given,
write(_New_angle),nl,!.
process(_Term,_Term).
Esta versión no prueba las condiciones previas de las reglas encontradas dos veces e incorpora un esquema diferente al lazo en Prolog. n [Ligeza, 1993] se propone una modificación del algoritmo básico de interpretación que permite el cambio flexible entre reglas. La idea es que si se dispone de conocimiento experto del dominio para reordenar las reglas, puede codificarse mediante la parte siguiente de las reglas. El significado de esta especificación es: si después de la ejecución de alguna regla es razonable escoger la ejecución de una sucesión dada de reglas, puede abandonarse temporalmente la búsqueda lineal básica y probarse primero las reglas especificadas. Este mecanismo permite un reordenamiento muy flexible y general de ejecución de las reglas. De hecho, se incorpora una cola LIFO (last in first out) dinámica en el mecanismo de control de razonamiento. Un intérprete "a dos niveles" que realiza la búsqueda y ejecución según esta estrategia puede ser:
run:-
write('LOOP NEXT RULES'),nl,
pick(_Number),
findrule(_Number,_Name,_Preconditions,_Negative_preconditions),
executerule(_Number,_Name,_Preconditions,_Negative_preconditions),
!,
run.
run:-
next([]),
write('LOOP LINEAR'),nl,
findrule(_Number,_Name,_Preconditions,_Negative_preconditions),
executerule(_Number,_Name,_Preconditions,_Negative_preconditions),
!,
run.
run:-
nl,nl,nl, write('No rule applicable; operation halted').
pick(_Number):-
next([]),!,fail.
pick(_Number):-
retract(next([_First|_Rest])),
eq(_Number,_First),
assert(next(_Rest)).
pick(_Number):- pick(_Number).
\end{verbatim}
Para una correcta ejecución, la cola next/1 debe estar inicializada,
por ejemplo, por una lista vacía. Otra modificación y extensión
del mecanismo propuesto pueden consistir en asignar a las reglas prioridades
numéricas y modificaciones dinámicas. Esto puede hacerse
especificando una función apropiada en la sección siguiente
de cualquier regla; entonces las reglas pueden ordenarse durante cualquier
ciclo de búsqueda con respecto a las prioridades actuales.
![]()