6.3 Fundamentos formales de la formación de
conocimiento
Abstracción de datos -- transformación de señales
en símbolos
Pasar de una caracterización extensa, detallada y precisa del
sistema supervisado a descripciones más abstractas, concisas y semánticas
es una práctica común es supervisión de procesos basada
en conocimiento. De hecho, las cantidades grandes de datos precisos pero
extensos son difíciles de comprender y tratar al nivel del conocimiento.
Es necesaria una abstracción de rasgos semánticos para mantener
la entrada de conocimiento al nivel del procesado de conocimiento.
La supervisión de procesos también puede percibirse como
un procesado de información a varios niveles; dependiendo del nivel,
se usa un lenguaje diferente para la representación de conocimiento,
interesan características diferentes y se emprenden acciones diferentes.
En el nivel más bajo, los lenguajes son relativamente simples
pero precisos; se usan guardar y manipular datos simples (normalmente números),
realizando operaciones simples, bien definidas (por ejemplo filtrado, calculo
del valor medio, varianza, etc.). Con estos lenguajes, los datos puede
representarse y procesarse, pero no puede especificarse ningún conocimiento
abstracto, general. En los niveles superiores, no hay ninguna necesidad
ni ninguna posibilidad de tratar con datos detallados; en cambio, el lenguaje
opera en lo abstracto, en términos simbólicos y cualitativos
y representa propiedades generales, como relaciones entre ellos. El poder
expresivo y las capacidades de manipulación de conocimiento dependen
del nivel de abstracción.
El problema importante es la reducción de la cantidad de información
mediante una apropiada abstracción de conocimiento semántico
a partir de una gran cantidad de datos. Hay varios enfoques, dependiendo
principalmente del tipo de datos de entrada, las herramientas aplicadas
y los objetivos propuestos. A continuación, se presentan brevemente
las operaciones más típicas desde un punto de vista matemático
general.
Para el tratamiento posterior, se supone un modelo de datos similar
al presentado previamente. Se supone que el modelo es de la forma de una
tabla relacional 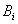 . Se
supone que se caracterizan las componentes de sistemas proporcionando los
valores de los atributos característicos en el instante i, o en
el caso de que la consideración explícita del tiempo no sea
crucial, sólo algún posible estado o el estado parcial del
sistema; es importante destacar que
puede referirse al estado total del sistema o describir simplemente solo
una parte de los parámetros del sistema. Así, el comportamiento
dinámico (comportamiento parcial) puede ser especificado mediante
una sucesión de estas tablas
. Se
supone que se caracterizan las componentes de sistemas proporcionando los
valores de los atributos característicos en el instante i, o en
el caso de que la consideración explícita del tiempo no sea
crucial, sólo algún posible estado o el estado parcial del
sistema; es importante destacar que
puede referirse al estado total del sistema o describir simplemente solo
una parte de los parámetros del sistema. Así, el comportamiento
dinámico (comportamiento parcial) puede ser especificado mediante
una sucesión de estas tablas 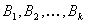 de longitud arbitraria, cada de ellas correspondiente a momentos consecutivos
de tiempo o a un estado diferente del sistema; esta sucesión se
denotaría como
de longitud arbitraria, cada de ellas correspondiente a momentos consecutivos
de tiempo o a un estado diferente del sistema; esta sucesión se
denotaría como 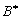 .
Si el tiempo no es importante, para denotar el conjunto anterior se escribirá
sólo B. Esta descripción engloba varias representaciones
frecuentemente usadas, por ejemplo sucesiones numéricas, vectores
de estado, datos codificados en forma tabular, etc.
.
Si el tiempo no es importante, para denotar el conjunto anterior se escribirá
sólo B. Esta descripción engloba varias representaciones
frecuentemente usadas, por ejemplo sucesiones numéricas, vectores
de estado, datos codificados en forma tabular, etc.
Sea Q un conjunto de etiquetas lingüísticas pensado para
denotar términos abstractos interpretados a nivel abstracto (que
tengan algún significado para los expertos del dominio), 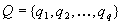 ;
los elementos de Q también pueden denotar ítems de cualquier
formalismo de representación de conocimiento específico,
por ejemplo formulas proposicionales, hechos atributivos de formalismos
lógicos, etiquetas cualitativas, etc., Las operaciones básicas
de abstracción pueden ser:
;
los elementos de Q también pueden denotar ítems de cualquier
formalismo de representación de conocimiento específico,
por ejemplo formulas proposicionales, hechos atributivos de formalismos
lógicos, etiquetas cualitativas, etc., Las operaciones básicas
de abstracción pueden ser:
-
Clasificación atemporal, etiquetado, reconocimiento de formas: En
este caso, simplemente se asigna alguna etiqueta cualitativa a cualquier
estado caracterizado por una tabla, la operación es de la forma:
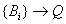 ,
la descripción detallada de la tabla
,
la descripción detallada de la tabla 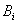 es "renombrada" y representada por un término lingüístico
es "renombrada" y representada por un término lingüístico 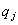 .
Este tipo operación se da en abstracción cualitativa de señales
(por ejemplo dividiendo un señal numérico en varias zonas,
como NB, NM, NES, Z, P, PM, PB), cálculo de algunos índices
cualitativos globales, reconocimiento de formas, etc., Destaquemos que
pueden asignarse a la misma etiqueta cualitativa
.
Este tipo operación se da en abstracción cualitativa de señales
(por ejemplo dividiendo un señal numérico en varias zonas,
como NB, NM, NES, Z, P, PM, PB), cálculo de algunos índices
cualitativos globales, reconocimiento de formas, etc., Destaquemos que
pueden asignarse a la misma etiqueta cualitativa 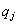 diferentes
(pero quizás similares) tablas
diferentes
(pero quizás similares) tablas 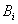 ,
agrupando varios estados en el mismo objeto abstracto. Por ejemplo, refiriéndose
al sistema del tanque simple presentado en la sección anterior,
cualquier nivel de agua se asigna a una de las cinco etiquetas
,
agrupando varios estados en el mismo objeto abstracto. Por ejemplo, refiriéndose
al sistema del tanque simple presentado en la sección anterior,
cualquier nivel de agua se asigna a una de las cinco etiquetas 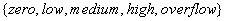 .
.
-
Clasificación temporal, evaluación de situaciones (reconocimiento):
Sea una sucesión
temporal de ciertos estados de
representando una parte de la trayectoria del sistema. La operación
de abstracción puede tomar la forma
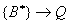 donde una sucesión o grupo (familia) de estados se asigna a una
sola etiqueta. Este tipo de operaciones se da cuando una señal continua
observada durante un intervalo de tiempo satisface ciertas propiedades
y es clasificada asignándole una etiqueta lingüística.
Algunos ejemplos de este tipo de abstracción son las características
cualitativas de señales como disminuir, mantener o aumentar; para
otros ejemplos pueden mirarse las secciones posteriores sobre episodios.
donde una sucesión o grupo (familia) de estados se asigna a una
sola etiqueta. Este tipo de operaciones se da cuando una señal continua
observada durante un intervalo de tiempo satisface ciertas propiedades
y es clasificada asignándole una etiqueta lingüística.
Algunos ejemplos de este tipo de abstracción son las características
cualitativas de señales como disminuir, mantener o aumentar; para
otros ejemplos pueden mirarse las secciones posteriores sobre episodios.
-
Caracterización atemporal: En este caso, a cualquier estado caracterizado
por una tabla simplemente
se le asigna un conjunto de etiquetas cualitativas (o incluso una estructura,
como términos, objetos de registro, marcos, etc.), esta operación
es básicamente de la forma:
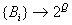 donde
la descripción detallada de la tabla se reemplaza y se representa
mediante un conjunto de términos lingüísticos que puede
organizarse en forma de alguna estructura. Este tipo de operaciones se
da en la abstracción cualitativa de señales mediante descripción
de varios rasgos cualitativos (tendencia, grado de oscilación, nivel,
etc.), en el cálculo de índices cualitativos globales, etc.
A destacar que varios subconjuntos de
donde
la descripción detallada de la tabla se reemplaza y se representa
mediante un conjunto de términos lingüísticos que puede
organizarse en forma de alguna estructura. Este tipo de operaciones se
da en la abstracción cualitativa de señales mediante descripción
de varios rasgos cualitativos (tendencia, grado de oscilación, nivel,
etc.), en el cálculo de índices cualitativos globales, etc.
A destacar que varios subconjuntos de 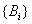 pueden asignarse al mismo conjunto de etiquetas cualitativas, pueden agruparse
varios estados en la misma descripción.
pueden asignarse al mismo conjunto de etiquetas cualitativas, pueden agruparse
varios estados en la misma descripción.
-
Caracterización temporal: Sea
una sucesión temporal de ciertos estados, representando una parte
de la trayectoria del sistema. La operación de abstracción
puede tomar la forma:
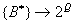 ,
donde una sucesión de estados se proyecta sobre un conjunto de etiquetas
(o, quizá, una estructura). Este tipo de operaciones se da cuando
una señal continua observada durante un intervalo de tiempo que
satisface ciertas propiedades se clasifica asignándole etiquetas
lingüísticas (por ejemplo asignándole varias etiquetas
como no-oscila y nivel-medio); también en los histogramas).
,
donde una sucesión de estados se proyecta sobre un conjunto de etiquetas
(o, quizá, una estructura). Este tipo de operaciones se da cuando
una señal continua observada durante un intervalo de tiempo que
satisface ciertas propiedades se clasifica asignándole etiquetas
lingüísticas (por ejemplo asignándole varias etiquetas
como no-oscila y nivel-medio); también en los histogramas).
-
Inducción de conocimiento: Este tipo de operación parece
ser significativamente diferente de los cuatro anteriores y, al mismo tiempo,
el más avanzado. En este caso la tarea es encontrar reglas generales
inducidas a partir de casos específicos, reglas que describan propiedades
generales y comportamientos del sistema, es decir, teoría del dominio
(quizá una teoría parcial). La transformación toma
ahora la forma:
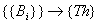
, donde {Th} es el conjunto de posibles teorías del dominio.
Algunos casos específicos de este tipo de abstracción incluyen
inducción de reglas e inferencia lógica inductiva.
Un caso específico de transformación de señales
en símbolos es el reconocimiento de formas clásico, donde
la entrada está en forma de imagen representada numéricamente,
y la salida es la clase a la que pertenece la imagen. Como es una situación
bastante específica, se menciona a parte - la representación
directa de imágenes a través de bases de datos, aunque posible,
sería bastante torpe.
Una clasificación similar se presenta en [Rakoto-Ravalontsalama
N., 1993] donde se mencionan los sensores simbólicos. No se
hace ninguna distinción entre etiquetado y caracterización.
Otro punto de vista en la transformación datos-conocimiento puede
estar motivado por el tipo genérico de herramientas a aplicar. Las
transformaciones funcionales como las anteriores pueden realizarse mediante
gran variedad de herramientas específicas, dependiendo del tipo
de señal, el enfoque seleccionado y los objetivos. Algunos de los
métodos más típicos pueden incluir: