4.15 Problemas genéricos para desarrollar un
sistema basado en conocimiento.
Problemas genéricos del desarrollo de sistemas basados en
conocimiento
Varios problemas deben ser resueltos para desarrollar y llevar a cabo un
sistema de supervisión basado en conocimiento; desde el punto de
vista de la ingenieria del conocimiento a escala abstracta estos problemas
pueden ser clasificados a grandes rasgos como sigue:
Representación de conocimiento: especificación del formalismo
de representación de conocimiento apropiado para las tareas consideradas,
Mecanismo de inferencia: especificación de las herramientas de procesado
del conocimiento adecuadas a los problemas a ser resueltos,
Mecanismo de control de inferencia: la definición de las restricciones,
estrategia de control y heurística que permitan un control eficaz
de la inferencia, y en particular evitando el problema llamado de explosión
combinatoria,
Adquisición de conocimiento: resolviendo el problema de cómo,
donde y quién adquirirá y elaborará el conocimiento
necesario para construir la base de conocimiento,
Diseño de la interfaz: comunicación hombre-máquina
y diseño y desarrollo de la interfaz, incluyendo la capacidad de
explicación de la inferencia y la justificación de soluciones,
Comprobación y validación: comprobación teórica
de la consistencia, integridad y exactitud del conocimiento, así
como su validación práctica en casos de prueba,
Modificación, adaptación y aprendizaje: mejora permanente
de la calidad del sistema desarrollado y adaptación a ambientes
cambiantes, incorporando capacidad de aprendizaje.
Todo los problemas anteriores deben ser considerados por el ingeniero
de conocimiento al intentar el diseño y desarrollo de un sistema
basado en conocimiento. Debe subrayarse que la selección de soluciones
puede ser de importancia crucial para la eficacia, calidad, fiabilidad
y seguridad del sistema.
Métodos de inferencia en sistemas basados en conocimiento
Algunos de los métodos seleccionados mas frecuentemente incluyen
los de inferencia lógica. A continuación se presenta una
lista de los mecanismos mas típicos de procesado de conocimiento
e inferencia:
generalización/abstracción,
especialización/substitución,
reconocimiento de formas, reconocimiento situaciones, valoración
de estados,
deducción (sistemas basado en reglas),
abducción (el método de Sherlock Holmes),
inducción (generación de conocimiento general, aprendizaje),
razonando basado en consistencia,
métodos de búsqueda para árboles y grafos,
métodos de búsqueda para grafos y conjuntos Y/O,
metodos de aprendizaje parametrico (NN),
métodos de inferencia difusos,
algoritmos de aprendizaje inductivo,
algoritmos de learning control (aprendizaje reforzado),
razonamiento basado en casos, razonamiento por analogía.
Aunque la lista no es completa, indica que puede aplicarse una gran
variedad de técnicas para el procesado del conocimiento en sistemas
inteligentes.
Representación del conocimiento - evaluación crítica
de las aproximaciones basadas en la lógica
En esta sección se argumentará que cualquier tipo de lenguaje
de representación del conocimiento no es nada más que otra
sintaxis, o ''syntactic sugar'' sobre lógica, y como tal podría
evitarse su reemplazo por una base de conocimiento lógica. Por otro
lado aquí se defiende la necesidad de diversidad de formalismos
de representación de conocimiento, incorporando características
no lógicas, como composición espacial y temporal, visualización
estructural, presentación jerárquica, etc. En primer lugar
se comentarán brevemente las técnicas de representación
de conocimiento existentes y se mostrara que prácticamente todas
ellas simplemente están basadas en lógica. Los libros clásicos
de IA enumeran normalmente los siguiente esquemas de representación
de conocimiento:
ítems de objecto-atributo-valor, hechos O-A-V ,
lógica, entendida principalmente como cálculo de predicados
de primer orden,
producción de reglas, o más precisamente sistemas basado
en reglas,
marcos, a veces llamados "
semánticos"; objetos (en programación
orientada a objetos también pueden ser considerados como tipos de
marcos y viceversa),
grafos semánticos en varias formas, donde los nodos representan
objetos y las uniones relaciones entre ellos,
escenarios, sobre todo para sistemas dinámicos,
En este capítulo se han recapitulado algunas de las técnicas
más populares y útiles en sistemas de supervisión.
Evidentemente, también son posibles combinaciones de estos métodos.
Revisemos brevemente los métodos anteriores en el contexto
de la lógica.
Los hechos del objecto-atributo-valor son simplemente otra sintaxis
lógica. Un hecho como a(c)=v, denotando el hecho que el valor del
atributo a para el objeto c es igual a v puede presentarse en forma lógica
como la formula atomica equal(a(c),v), o holds(fact(a(c),v)), etc. Es más,
usando lógica pueden codificarse fácilmente relaciones tres-,
cuatro -, y n-arias, como between(two,one,three) o four_in_order(1,2,3,4)
qué no es necesariamente tan fácil en el formalismo O-A-V.
Más allá, la lógica proporciona una manera de representar
listas, y así hace posible tratar con conjuntos y secuencias; una
lista [a,b,c,d] es una forma breve para .(a,.(b,. (c,. (d)))), donde .
es un símbolo funcional binario seleccionado para listas empaquetadas
(como en lenguajes tipo LISP) y se aplica una notación fija.
Con respecto a las reglas, consideremos las reglas básicas 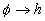 donde
donde 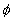 es la condición
previa y
es la condición
previa y 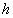 es la conclusión;
desde el punto de vista lógico esta regla puede representarse como
implicación
es la conclusión;
desde el punto de vista lógico esta regla puede representarse como
implicación 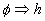 que,
cuando se aplica (por ejemplo con el principio de inferencia modus ponens)
produce un efecto equivalente a la aplicación de la regla correspondiente.
que,
cuando se aplica (por ejemplo con el principio de inferencia modus ponens)
produce un efecto equivalente a la aplicación de la regla correspondiente.
Volviendo a los marcos, debería echarse una mirada a la estructura
de esta construccion. Frecuentemente, consiste en la especificación
de cierta descripción de objetos con facetas y slots y una parte
operacional que contesta a las preguntas if-needed, if-added, if-modified,
etc. La primera parte normalmente es como una estructura del tipo registro,
formando alguna jerarquía, y proporcionando ciertos valores que
caracterizan el objeto descrito. Esto puede representarse perfectamente
con una estructura de términos arbitrariamente complejos, siguiendo
el modelo:
o similar; si es necesario, las listas también pueden
ser fácilmente modeladas. La parte procesal puede ser principalmente
modelada especificando un componente inferencial con reglas que especifiquen
las consecuencias de ciertas acciones (si es posible), o debe agregarse
como un conjunto externo de subprogramas que modifiquen la estructura lógica;
ésto también puede hacerse en lógica del primer orden,
pero en este caso la especificación se expresará en meta-lenguaje,
refiriéndose a los objeto de la estructura básica como elementos
de manipulación.
Finalmente, los grafos de modelado también puede llevarse a cabo
dentro de la lógica. Considere un gráfo general compuesto
de nodos y arcos etiquetados. Cualquier componente es de la forma:
qué es la conexión básica del grafo. Obviamente, puede
ser modelado mediante una formula atómica relation_ij(node_i,node_j),
o, aun más generalmente como holds(relation_ij,node_i,node_j). El
gráfico entero puede ser modelado como un conjunto(lógicamente:
conjunción) de tales declaraciones; aun mas, pueden agregarse algunos
descriptores auxiliares como parámetros adicionales..
Para completar el resumen, mencionemos algunos rasgos específicos
de lógica, apenas encontrados en otros formalismos. La lógica
define claramente sintaxis y semántica. Una cosa importante es que
esta lógica no sólo es un formalismo de representación
de conocimiento, sino también es una herramienta de procesado de
conocimiento; la deducción automatizada proporciona el entorno para
resolver problemas. Aun más, las reglas de deducción tienen
la propiedad de producir salidas válidas, se generan sólo
salidas correctas. Y por último, pero no menos importante, no es
difícil proporcionar un sistema de deducción que sea completo,
si una fórmula (solución, hipótesis, etc.) sigue de
los axiomas, entonces él (o su forma generalizada) puede deducirse
de los axiomas dentro del sistema; en otras palabras, si la solución
existe, puede encontrarse.
La pregunta es: ¿si el marco de la lógica es tan positivo,
deberíamos, y - en ese caso - por qué, considerar otro formalismo
de representación de conocimiento? En otras palabras, ¿por
qué la lógica no es suficiente para la representación
de conocimiento?, ¿cuales son sus limitaciones y cómo podemos
mejorar la situación?, ¿qué características
adicionales deben tener los mecanismos de representación del conocimiento?.
La respuesta a esta pregunta es, como de costumbre, compleja y algo subjetivo.
Pero en sistemas de supervisión basados en conocimiento, sobre todo
los que involucra operadores humanos, cooperación hombre-máquina
y cooperación experta, la respuesta a estas preguntas comprende
factores cruciales para el diseño y aplicación de sistemas
agradables y útiles para el usuario.
A continuación se presenta una lista de características
consideradas como inconvenientes de la lógica clásica:
Sintaxis difícil y, a veces, ambigua, escasamente aceptable por
parte de operadores humanos. Esto proviene del hecho que aprendemos a pensar
funcionalmente, en términos de: el resultado de esto es esto otro,
pero no relacionalmente, en términos de: esta relación se
cumple para estos objetos. Principalmente no han enseñado matemáticas,
no lógica.
Las personas piensan a menudo sobre la base de la intuición; un
fenómeno común cercano para usar en razonamiento es la causalidad.
La lógica, por si misma, permite la especificación de dependencias
causales, pero no proporciona ningún mecanismo de representación
intuitiva y tratamiento de la causalidad; el orden (posicion) de los argumentos
en los predicados no es suficiente para ello.
Las personas especifican y usan a menudo dependencias jerárquicas
para representar conocimiento. De nuevo, la lógica es ''pobre'',
no apoya el tratamiento de jerarquías de forma simple y natural.
Las fórmulas lógicas tienen una estructura monótona,
llana, todos los elementos son igualmente importantes; a las personas les
gusta presentar la información de forma estructural, que ayude a
percibir y comprender el conocimiento representado.
La lógica no tiene ninguna forma de visualización: la representación
visual es importante para las personas, la mayoría de la información
(mas del 80 \%) pasa por los ojos en forma de imágenes. La presentación
espacial hace más fácil y más leíble la representación
de conocimiento. Además, las relaciones espaciales pueden modelar
ciertas relaciones importantes, por ejemplo, en grafos, la distancia entre
los nodos puede modelar la distancia real entre pueblos. La información
desplegada espacialmente ayuda a percibir rápidamente y a analizar
ciertas características globales, por ejemplo la existencia de conexiones,
áreas, formas, etc. La visualización ayuda a organizar i
ordenar el conocimiento.
La lógica es inflexible y dura para especificar ciertos aspectos
específicos del conocimiento, como incertidumbre, la vaguedad, confusión,
fuerza, etc.,
La lógica está lejos de las herramientas cotidianas, es demasiado
general, mientras que para las tareas específicas necesitamos herramientas
más específicas (gráficos, dibujos, colores, etc.),
La lógica clásica no cubre directamente inferencia por defecto
y no-monotonía, y así el modelado estos problemas es prácticamente
difícil.
Es difícil controlar las estrategias de deducción; la explosión
combinacional ocurre fácilmente, y la forma de presentación
de conocimiento (sintaxis) no ayuda. A veces, las respuestas a preguntas
simples son muy difíciles de encontrar.
La lógica no soporta el cálculo de forma simple y directa;
sin embargo ésta es, a menudo una necesidad básica.
La lógica no soporta inferencia cualitativa directa, muy importante
cuando se trata con información imprecisa y razonamiento a los niveles
de abstracción altos.
Finalmente, la lógica es estricta, y si se da inconsistencia, resulta
inútil (un error); mientras, ciertos tipos de inconsistencias forman
parte de lo cotidiano y los seres humanos las manejan fácilmente.
Los puntos anteriores resumen sólo algunas de las carencias más
cruciales de la lógica clásica. Muchos de estos puntos son
tratados o resueltos por los modernos tipos de lógica extendida
o modificada, como lógica difusa, las lógicas multivaluadas,
lógicas no-monotonicas, etc.,
Algunas herramientas gráficas para apoyar la representación
de conocimiento incluyen:
mapas de flujo, diagramas de flujo, gráficos de flujo, etc., representación
simbólica del flujo de señales y transformaciones en el sistema,
esquemas funcionales, incluyendo representación gráfica realista
de componentes del sistema (diagramas de flujo tecnológicos),
grafos de la transición de estados,
árboles de decisión, árboles binarios,
tablas de decisión,
tablas de decisión (atributo-valor),
representación gráfica de variables del proceso, etc.,
Debe destacarse que, para sistemas más complejos, sólo pueden
proporcionar resultados satisfactorios aquellas técnicas de representación
de conocimiento que mejor encajen con las características del sistema
supervisado y los requisitos específicos en curso. Aún más,
una interfaz gráfica de usuario con componentes de procesado inteligente
del conocimiento constituye hoy día un componente decisivo de cualquier
sistema basado en conocimiento.
