1.1 Introducción a la supervisión de procesos
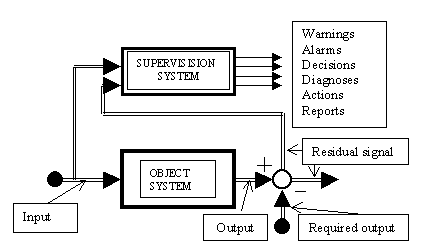
La creciente complejidad de los sistemas controlados por computadora
y los requerimientos de calidad, fiabilidad y seguridad hacen necesaria
la aplicación de sistemas de supervisión. La Supervisión
consiste en la observación (monitorización) continua de las
salidas del sistema y posterior comparación con las deseadas (definidas
por el usuario); en el caso de detección de comportamientos no deseados
deben efectuarse las acciones apropiadas para corregirlos. La Supervisión
se considera aquí como un nivel superior de actividad importante.
El esquema general para el concepto de sistema de supervisión se
presenta en la figura .
Los sistemas de supervisión constituyen un nivel superior al del control; están pensados para facilitar el procesado de información, la comunicación hombre-máquina, la percepción y el análisis de señales, la evaluación del estado del proceso y, finalmente, la toma de decisiones.
La supervisión de procesos es probablemente tan antigua como su control. De hecho, el control en lazo cerrado utiliza la supervisión elemental para mantener los valores correctos de la entrada que puedan compensar ciertas desviaciones en la salida; es por ello que normalmente es mejor que el control en lazo abierto, sin elementos de supervisión. Normalmente, sin embargo, la supervisión se considera separadamente al control, que por si solo puede ser avanzado (por ejemplo, control óptimo). La supervisión es vista como un nivel superior de actividad respecto al del control.
De forma similar al control, la supervisión puede estar basada
en modelos matemáticos clásicos y en el procesado numérico
de señales, o puede incluir traducción de señales
en símbolos, procesado de información simbólica, componentes
de ingeniería del conocimiento e inferencia inteligente. En general,
según las principales herramientas y métodos utilizados para
procesar la información, los sistemas de supervisión pueden
estar divididos en dos grandes grupos:
- Supervisión Clásica, basada en el procesado numérico de señales, y
- Supervisión Inteligente o basada en conocimiento, que utiliza representación simbólica del conocimiento e inferencia.
La supervisión clásica tiene su origen en la teoría
clásica de control, en la estadística y en el procesado de
señales. Su solidez reside en la utilización de modelos y
métodos bien definidos, cálculos precisos y herramientas
computacionales normales. Sin embargo, encuentra dificultades en el tratamiento
de datos no numéricos, gran cantidad de datos, modelos matemáticos
poco precisos, desconocidos o demasiado complejos o cuando los métodos
matemáticos son irrelevantes. Además, en algunos casos la
comunicación hombre-máquina resulta difícil, puesto
que los expertos humanos razonan típicamente a nivel simbólico.
La Supervisión Basada en Conocimiento, por otro lado, maneja conocimiento simbólico, considerándolo tanto como entrada o salida como componente del sistema. Sus raíces pueden remontarse a los dominios de la Inteligencia Artificial (AI), especialmente a la Ingeniería de Conocimiento (EC), la lógica y varias ramas de la informática; por supuesto, también tiene sus raíces en del dominio del control automático, especialmente en el control digital y la teoría de autómatas. Otras conexiones pueden ser el cálculo lingüístico, las bases de datos, los métodos algebraicos, etc. La entrada básica para un sistema de supervisión basado en conocimiento consiste en datos simbólicos. Estos datos pueden obtenerse directamente del proceso o pueden generarse como resultado de una transformación de señales numéricas a forma simbólica. El procesado del conocimiento puede tomar la forma de uno o varios modos de inferencia automatizada. La salida de estos sistemas es típicamente simbólica o gráfica, fácil de entender por los operadores del proceso. Como soporte al procesado de la información pueden utilizarse algunos mecanismos de inferencia simbólica; los mas importantes desde el punto de vista de la supervisión se comentaran mas adelante. La supervisión basada en conocimiento también es llamada supervisión inteligente, ya que los métodos de procesado de la información están basados en procesos similares típicos de los seres humanos.
Supervisión basada en conocimiento: un poco de historia
Probablemente, el primer artículo importante expresando la idea de aplicar métodos propios de la Inteligencia Artificial (AI) al control de procesos fue el de Fu. Mas tarde aparecieron mas articulos teóricos y alguna aplicación de laboratorio, especialmente en dominios como la planificación.
Uno de los primeros sistemas aplicados descrito en la literatura fue el Ventilator Manager (VM). VM era un sistema en tiempo real y en línea, desarrollado para la interpretación de datos fisiológicos en una unidad del cuidado intensivo. Un sistema de monitorización automático proporcionaba a VM los valores de 30 datos fisiológicos con un tiempo de muestreo de 2 y 10 minutos. Estos datos se utilizaban posteriormente como soporte al cuidado de pacientes post-quirúrgicos que recibían ventilación mecánica asistida. La salida de VM consistia en sugerencias a médicos y generación de informes periódicos. Se aplicaban técnicas de encadenamiento hacia delante, verificando si la información temporal (adquirida anteriormente) todavía era válida, e interpretación cíclica de reglas.
En los ochenta fueron desarrollados varios sistemas de supervisión
que apoyaban a o incluían decisión y control basados en conocimiento.
Una buena revisión de los problemas considerados y sus aplicaciones
se da en [] donde se incluyen aplicaciones en industria aerospacial, comunicación,
sistemas médicos, control de procesos, y robótica. También
se perfilan brevemente las herramientas y técnicas usadas. Uno de
los problemas teóricos del articulo fue la definición y discusión
de problemas relativamente nuevos acerca del tiempo real en sistemas basado
en conocimiento, contrastando estas aplicaciones con aquellas que operan
con conocimiento estático. Se consideraron los siguientes problemas:
- No monotonía (conocimiento temporal),
- Funcionamiento continuo
- Eventos asíncronos (interrupciones, reactividad),
- Ambiente externo,
- Datos inciertos y perdidos,
- Actuación alta,
- Razonamiento temporal,
- Enfoque de atención,
- Tiempo de contestación garantizado,
- Integración con componentes procesales.
Cada uno de estos problemas debe ser resuelto específicamente.
Además debe tenerse en cuenta la complejidad asociada a la gran
cantidad de señales de entrada (500 analógicas y 2500 digitales
en una plataforma petrolífera, pudiendo llegar a mas de 20,000 en
otros casos) y a los requerimientos de contestación (100 milisegundos
en algún caso). Otro problema lo constituye la excesiva cantidad
de datos: imaginemos la supervisión de una turbina que rueda a 30,000
rotaciones por segundo. Si los sensores de desplazamiento nos dan 8,000
medidas por segundo y la conversión A/C usa 8 bits, disponemos de
8kB de datos por segundo, alrededor de 28 MB por hora, y finalmente 0,7
GB por día de observación. Si la información no se
pre-selecciona, comprime y procesa en línea para obtener datos más
concisos, semánticos o cualitativos, el almacenamiento y direccionamiento
de datos representa un serio problema.
El Desarrollo y aplicaciones de sistemas basados en conocimiento y métodos de supervisión, control, diagnóstico, y apoyo a la toma de decisiones en procesos de fabricación constituye actualmente una area de conocimiento muy extensa.
Obviamente, el control, la supervisión y el diagnóstico se realizan para obtener ciertos resultados: el básico es que es el producto final, o salida, cumpla con los requisitos de cantidad y calidad. Además también pueden considerarse otros aspectos como el esfuerzo humano, protección del medio ambiente, minimizar costes, eficacia óptima, etc. De hecho, la calidad del proceso y del producto parece ser un factor que atraen ahora la atención. ¿Pero que es la calidad?
Debe definirse la calidad en términos de características posibles de evaluar, condiciones que deban ser satisfechas o criterios comparativos. Varios acercamientos son posibles: índices de calidad numéricos o simbólicos, características de atributos múltiples, especificaciones de requisitos mínimos, etc. Sólo después de definir la forma de evaluar la calidad podemos hablar sobre las posibilidades de mejorarla. Para ello, deben identificarse los factores que influyen en la calidad y su influencia en los índices debe ser aprendida o determinada mediante modelos. Además, deben especificarse el alcance de las posibles modificaciones y sus limitaciones y restricciones. Sólo entonces podemos intentar mejorarla.
Para realizar el procedimiento anterior deben estar disponibles ciertas
herramientas. Estas herramientas incluyen, pero únicamente, sistemas
generales y terminología específica, lenguajes y formalismos
para la representación de los datos y del conocimiento, modelos,
herramientas de procesado de datos y conocimiento y procedimientos de evaluación.
El objetivo de este trabajo es la presentación y discusión
de una selección de estas cuestiones.
![]()