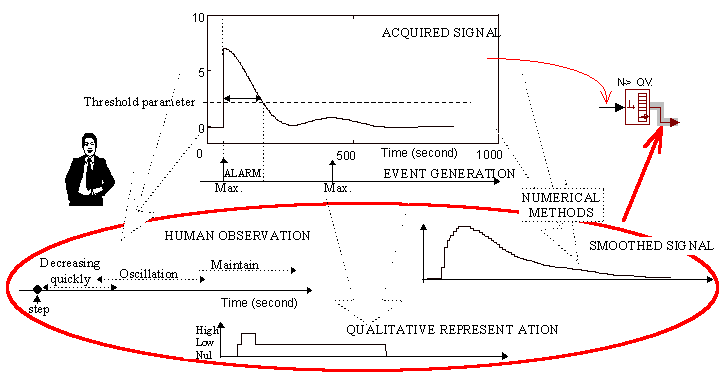
Fig. .1 Multiple representation of
a process variable and information related.
Sharing Information between tools : Object-variables.
Data encapsulation is one of the basic features of OOP. That is why the classical approach of OOP in large applications ensures better structuring and organisation. In this work, encapsulation is used to offer a multiple representation of data for avoiding data type conversion and additional processing using object structures in the definition of process variables. With this goal the concept of object-variables is introduced. The aim of object-variables is to provide the adequate representation of process variables for any tool that require information related to them. An additional contribution of this work has been done in demonstrating the viability of using these object-variables in a commercial package, MATLAB/Simulink working together with numerical and knowledge-based tools under a graphical block representation.
Using process variables for reasoning.
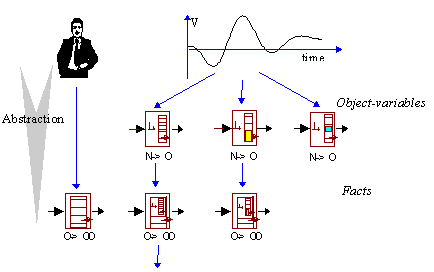
Expert reasoning about process behaviour is usually not only associated to selected, isolated values of process variables at a certain instant of time, but also takes into account the whole process dynamics, including their history, trends, numerical and qualitative characteristics, limitations, etc., together with their influence on the behaviour of other individual process variables. Such inference, therefore, becomes easier if all information from the process is clearly encapsulated and located Organisation of process related information must be done according to multiple sources of information (sensors, analytical models, human experiences, etc.), then different units for encapsulation of information can be defined. Taking this into account, it seems reasonably that all information concerning process variables should be encapsulated in template structure. Thus, any information related to this process variable would be accessible. This means that the values of process variables supplied by sensors or simulation tools should be encapsulated with all information related to them. Parameters, units, landmarks, qualitative characteristics and additional knowledge supplied with the variables can facilitate the interpretation of process behaviour providing all the auxiliary information concerning the analysed signal grouped together. Further, when designing architecture for supervision and control, sometimes different tools can use the same variable values, but simultaneously the variables are analysed at different level of abstraction (depending on current needs, numeric values, tendencies, deviations, qualitative values, event generation, alarms, etc. can be considered.). See Fig.1. Unfortunately, those different tools are not provided with methods to obtain this information from purely numerical values given by sensors. This auxiliary calculation must be performed outside of those reasoning tools what further causes an interfacing problem to occur.
Fig. .1 Multiple representation of
a process variable and information related.
To summarise, the problem consists in the necessity of multi-aspect representation of knowledge about process variables. The main issues include the following:
The object oriented approach seems to offer the solution thanks
to its capability of encapsulating structured data and methods in the same
structure. Using this approach in the definition of template structure
for process variables, basic necessities, as mentioned above, can be covered.
Process variables at different levels of abstraction : Object-variables.
The proposed solution for solving the necessity of this multi-aspect representation of process variables presented in this thesis consists in embedding not only numerical values of variables (measures, estimations, history, indices and so on) and parameters (thresholds, landmarks, ranges, etc.), but also methods for obtaining the adequate description of signals behaviour for each tool (signal processing and reasoning algorithms, abstraction tools), and methods for manipulating and accessing this information.
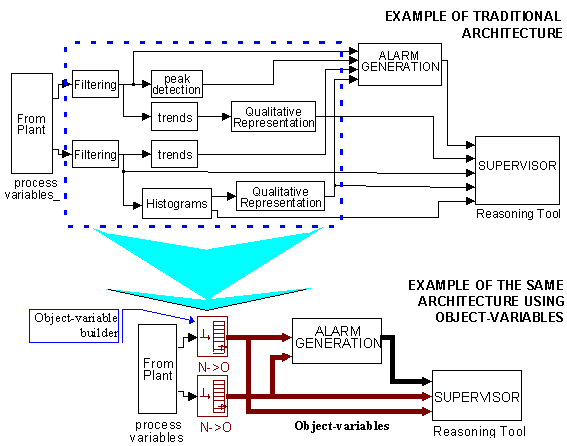
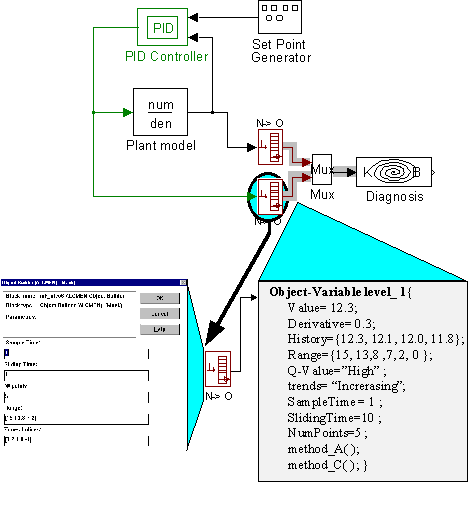
Hence, variable values, parameters and methods will be encapsulated in the same object structure, to be called an object-variable See "Fig. 1 and Fig. 2". Thus, the same variable is shared by various tools providing the adequate information (representation) for each of them. The Object-oriented approach gives the possibility of representing one variable as a single entity with its multiple representation and related information, such as methods and parameters, in a very flexible and powerful way.
Uses a similar proposal for representing process components that can be used in a different context and that can only be represented once in a knowledge base (they are called multi-view objects). Object-variables are used with a similar goal to encapsulate in one object information and representation of the same variable at different levels of abstraction. Whereas multi-view objects are focused on the description of the plant and the user must insert this description for further use, object-variables are used to automatically abstract and store information from process variables. They are dynamically actualised.
Since the embedded information in an object-variable is obtained directly from the numerical signals after performing certain simple operations (with use of abstraction tools), sometimes external parameters are necessary. These parameters must be supplied to each object-variable in order to provide the process knowledge concerning this variable. This kind of knowledge is necessary to distinguish certain variables of processes. For instance, a control variable of a level regulation process is qualitatively different from a DC motor speed control variable, but both could be acquired as a voltage in the range of 0 to 10 volts.
The blocks, labelled as "N->O" in the figure, perform this conversion. Objects are built from numerical variable values according to the object-variable definition and supplied parameters. Therefore, the output of these blocks is not numerical data but it constitutes object-variables, and all information embedded in them is accessible for the connected blocks. The figure, represents how two object-variables are supplied to a diagnostic block.
About objects in MATLAB-Simulink. Containers.
The idea of using objects in MATLAB was firstly put forward in introducing the use of containers. This work presents containers, which have some of the commonly accepted properties (but not all) of the objects, to represent object-oriented models. Those containers are used to solve data management problems in a programming environment for control systems analysis and design, selecting MATLAB as a test-bed. The benefits of using containers in CACE frameworks are also discussed in.
The features of containers common to objects are :
After the work , the evolution of MATLAB has always pointed to the
idea of incorporating object structures. In fact, the new version (MATLAB
5.0) is supplied with five different classes of data and offers the possibility
of creating new classes defining a MATLAB structure that provides data
storage for the object . These objects have some of the basic properties
assumed for objects such as inheritance and overloading of the operators.
Another important characteristic of objects, is the encapsulation of methods and data in the same structure (maybe the most important feature of objects). The benefits of this property in a CACE framework are also discussed in. Despite of the importance of this feature, objects incorporated in MATLAB 5.0 do not provide this possibility. In fact, methods to deal with the desired objects must be defined apart form MATLAB objects, in separated files (*.M, MATLAB files) and stored in a specific directory. Due to this drawback Simulink 2.0 .deals only with numerical data at its input and output, reducing the applicability of this framework to numerical simulation and analysis. In case of applications to complex information processing, including elements of symbolic reasoning, the approach provided in the recent version of MATLAB is still far from satisfactory. Despite of improved graphical capabilities and the possibility of inheritance in some parameters (sample time, number of input and output), the use of Simulink as an Object oriented Computer aided control system design framework (OOCACSD) is still far, because of its poor capability of managing objects as variables.
The idea presented in this work is slightly different from the one of container since real objects are defined, using an external language, in MATLAB/Simulink. These objects are applied mostly to the description of variables supported by a Simulink block representation (graphical representation). The solution presented in this work is necessary for several tasks, such as supervision or diagnostic applications where tools need to operate on different kinds of data (qualitative, symbolic, numerical, logical, textual), representing the same process variable.
The use of object-variables is defined to encapsulate information (data and methods) into a data structure to be shared among different tools. It is assumed that an open architecture is used and new tools can be added into the framework. Then, new features may be required to describe system variables and object-variables must be endowed with new methods to supply them. Taking this into account, two possible solutions to modify the structure of object-variables are proposed below.
The first solution is a straightforward one. It consists in adding new features to the original object-variable, in order to obtain the capabilities required for any newly added tool. In this case, the data structure grows in size and some memory is likely to be wasted, even though not all features will be used but only some of them. This solution, although applicable directly, is not recommended in case of complex systems because of the great number of variables involved.
The second possibility is to define several object-variables with a simple common structure and particular methods to serve sets of tools with some similarities. This option allows to define more accurate object-variables, fitting the tool requirements in a more exact way; unfortunately in some cases a certain degree of incompatibility with certain tools may occur and more than one object-variable could be necessary to be used for representing several features of a process variable. Both possibilities are represented "Fig. 6".
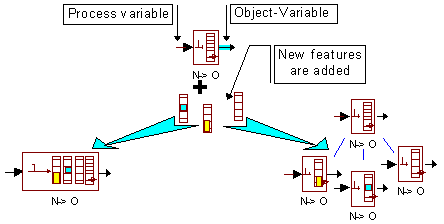
Fig. .6 Obtaining New object-variables from a basic structure.
|
Object- Variables
|
|
|
|
|
|
Information
|
|
|
|
|
|
Data
|
|
|
|
|
|
Methods
|
|
|
|
|
|
Tools
|
Filters |
Simulation |
|
|
Due to the relevance of embedding objects into Simulink in respect to this work a brief explanation is added as technical note. Through the mechanism of S-functions defined in Matlab/Simulink, the user can add new general purpose blocks or incorporate an existing 'C' or 'FORTRAN' code into the simulation. The only constraint which must be taken into account is that the new code must be written with respect to the predefined structures or routines. These routines will be called by Simulink at each simulation step.
'SimStruct' is the data structure used by Simulink designers to encapsulate the blocks information. Each block in a Simulink representation has an associated SimStruct, accessed by Simulink to perform simulations correctly. Then, the information embedded in this data structure allows Simulink to know the parameters associated to this S-Function, as well as to access user defined routines.

There are three fields where the user can save restricted information in the 'SimStruct' structure, only available for the object owner. These three fields are associated with work vectors that correspond to pointers to integers (int *), to doubles (double *), and pointers to void pointers (void **). In the 'SimStruct', see "Fig.10", these fields are labelled as 'vectors.RWork', 'vectors.IWork' and 'vectors.PWork'. Therefore, the only method to embed external information into Simulink 'SimStruct' consists in using these working vectors.
By taking advantage of this capability, it is possible to associate an object to Simulink blocks by saving a pointer (to this object) in the 'vector.Pwork' field in its 'SimStruct'. Moreover, to each Simulink block there can be an object associated.
In order to assure correct work of the components together, some further constraints must be taken into account. The source file for getting a .MEX file (as a result of a compilation of an S-function), is structured according to a template structure defined by Simulink developers. This structure is composed of routines where the user can insert his own code. In these routines of the .MEX file under design the following advice must be taken into account:
| #include "obj_def. h" | Class definitions and object access methods can be defined in an include file. |
| mdlInitializeSizes() | A pointer vector will be used and specified using the command 'ssSetNumPWork(S,1)'. |
| MdlInitializeConditions() | Memory space must be allocated, to be used by the object and its pointer. |
| mdlOutputs() | Methods could be activated to access the desired fields into this routine. |
| mdlUpdate() | To update and fill the predefined fields of the object. |
| mdlTerminate() | Remember to free allocated memory. |
Table -2 Structure of a C written S-function.
The fact of working with objects implies using an object oriented compiler, and at the same time, access to data pointers (C++ compiler) must be allowed. In this case, Watcom 10.5 C++ compiler was chosen.