Case-based reasoning (CBR) constitutes and approach to reuse existing knowledge for solving new problems. In many complex problems existing solutions were obtained as the result of long period experiments, application of knowledge coming from several sources, application of hard to formalise knowledge of different types, etc. The working solutions are based on extensive experience, trial and error approach, intuition and personal experience of domain experts, companies know-how, etc. - but no formal model exists and the knowledge cannot be easily "codified", e.g. in a form of set of rules. In such cases one of the most promising approaches consists in application of the existing knowledge about similar cases (problems) to solving the new ones, perhaps after adjustment or modifications (if necessary). This is also the case of high level supervision performed for processes of complex nature and having no precise mathematical models, where the expert experience, knowledge and intuition leads to safe and satisfactory control. Simple reuse of that knowledge can constitute a constructive approach for efficient supervision.
One of the problems concerning development and practical applications
of expert systems consists in difficulties with knowledge acquisition (the
so-called knowledge acquisition bottleneck or knowledge elicitation
bottleneck). There are several reasons for obtaining useful, correct,
complete and consistent set of rules for problems solving (although if
this is feasible in certain domain, a powerful system can be build); some
of most typical include the following ones:
Further, there are problems with fine tuning the system to provide
correct solutions to a large variety of specific tasks, while sometimes
the a priori encoded knowledge does not provide subtle details so that
the system is capable of differentiating between specific similar problems
with different solutions.
Case-based reasoning is a general ''ideology'' consisting in recognising the need to use, learn from and reuse in a creative way knowledge in form of particular cases already solved. It simultaneously constitutes an attempt to solve , at least partially, the above problems. Case-based reasoning (CBR) tends to represent knowledge about specific cases and makes reuse of formerly obtained solutions to refine, correct or guide the search for solution of current problems.
CBR is not a unique well defined methodology; depending on the problem and knowledge representation as well as the model of the system there exists various ways of application of CBR. It can be used as independent method or for supporting and enhancing existing tools.
As an independent method, CBR requires selection of good knowledge representation at first. The individual cases, consisting of problems and their solutions should be encoded in a way allowing for efficient search. The search for a specific case, however, cannot be based on simple database retrieval techniques; these techniques are to restrictive and in most cases they are unable to find "similar" or "analogical" cases. Thus, the knowledge representation must support flexible knowledge retrieval, not only identical but "sufficiently close" to the search pattern as well.
Moreover, knowledge representation must support the possibility to modify or adjust the existing solution so that it can be applied in the specific case under consideration. Thus the reuse of knowledge must comprise elements of creativity. Some further elements consists in appropriate revision of the final solution and storing it in an appropriate form in the knowledge base for further use.
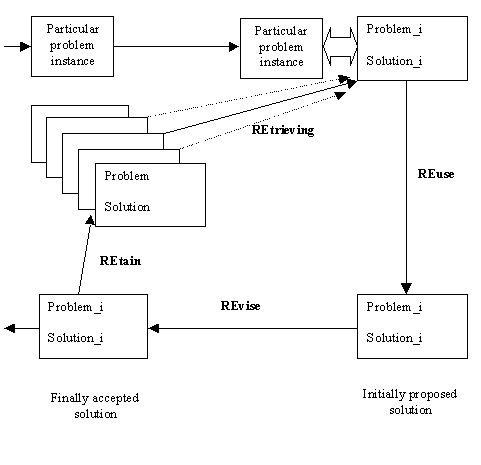
In general, it is said that the CBR approach comprises the following
for RE-activities:
The basic cycle of CBR can be illustrated with use of the following
figure:
The detailed operations consist to a great degree of the specific form of knowledge representation. In the simplest cases classical relational database scheme for knowledge representation can be applied. In more complex systems object-oriented databases or frame-like structures can be used for case storing. Also the retrieval mechanisms depend much on the knowledge representation method accepted. For example, "soft" retrieval can be based on certain similarity measures, including various definitions of distance and fuzzy measures of diversity. Also case adaptation methods may vary from simple parameter adjustment to structural modifications. CBR can be augmented by all the AI inference techniques, including pattern matching procedures, search, inductive generalisation and learning, parametrical learning, logical inference and other.Below an approach to CBR for enhancing the power of hierarchical expert system is outlined as an example approach; the presentation is based on [Bach and Allemang, 1996].
A hierarchical expert system is based on the notion of hierarchy of categories, similar as classes and sub-classes in object oriented programming or types in sorted theories. The basic structure inside such a system is similar to decision tree, where intermediate nodes correspond to specific classes. Traversing down the tree, more and more specific classes are encountered. Finally, the leaf nodes represent individual concepts, decision, or any further indivisible items of interest. System organised around this scheme are very useful for categorisation and classification tasks of various sorts (situation assignment, pattern classification, diagnosis, etc.).
In order to make the processing constructive, at any non-leaf node a test, question or formula for evaluation and further specification of the sub-class is provided. Such a system can be used in a number of decision making tasks, while diagnostic inference seems to be a prominent example.
The work of such system, however, is not free of errors. The most typical ones include:
The most frequent errors correspond to possibilities 2. and 3. Further, two more precise types of errors can be defined:establishing wrong leaf node. establishing multiple leaf nodes including the correct one. establishing no leaf nodes. lack of nodes corresponding to considered category. In order to help the system deal with these kinds of faults, a CBR mechanism is incorporated in the tree. The basic idea consists in storing and reusing correctly classified cases.false positive faults: some fault was established while in fact the fault does not occur, false negative faults: some node was not established, while in fact the corresponding fault occurs. A case is a set of facts (e.g. variables values measured on the system) together with the correct decision. Each node of the hierarchy points to a corresponding list of cases, and for any case there is information about whether is a positive or negative case with respect to the category assigned to the node. Then, the CBR mechanism performs three basic cases:
The set of positive and negative examples constitutes a valuable auxiliary knowledge guiding and refining the search. On the other hand, the hierarchical system can be interpreted as a case index for fast retrieval of specific cases.Retrieve: in this case the CBR is used to eliminate false negative classifications. This means that if a node is rejected, in order to avoid rejecting a node describing in fact true class, the set of cases is examined. Then some evaluation, e.g. statistical or heuristic can be used to assign the potential for the considered node covering the positive classification. Re-use: the concept consists of the possibility of using the knowledge contained in cases, even when it is inconsistent with the expert knowledge (overriding the expert knowledge); some most specific rules covering the relevant cases are generated (the so-called association rules), and they are checked against the all relevant cases, to evaluate its accuracy and significance. If the rule is highly reliable, it can override the expert knowledge. Store: this is a part of learning consisting in storing cases, but note that the specific cases must be stored in appropriate places in order to make right use of them. Storing is performed in two stages: first, a node responsible for wrong classification is identified (blame assignment; identification of the node responsible for missing the correct answer), and second, modification - how to avoid the failure is decided, i.e. the specific case is added to the list of cases for each node on the correct path for the case, as a positive example for that node. For every other node established in the system the case is added as a negative example