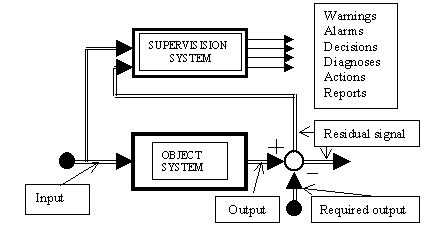
Fig. -1 A general schema of supervision system.
The control system is not shown in this figure; instead, only input signal coming from the control system is indicated. The output signal is compared with required output and the residual signal constituting an indicator of goal satisfaction at time instant is generated. The supervision system monitors the residual; sometimes it is also necessary to monitor the current input (e.g. for identification of the current stage and mode of control or in order to verify if an observed misbehaviour may be caused by improper control). The supervision system generates warnings, alarms, diagnoses, decisions, actions and may be applied to generate reports, etc.
Supervision systems, constituting upper-level with respect to direct computer control level, perform advanced process monitoring and classical as well as intelligent (knowledge based) supervisory functions. They are intended to provide extended automatic information processing capabilities and support man-machine communication, signal perception and analysis, state evaluation and process understanding and, finally, decision making support and decision execution.
1.1.1 Classical vs. Knowledge-based supervision
Process supervision is probably as old as process control. Note that closed-loop feedback control uses in fact elementary supervision of the results of applied control to maintain correct input which can compensate for certain deviations of the output signal; this is why it is normally better than "blind" open-loop control having no elements of supervision at all. Currently, however, supervision is usually considered separately to control, which itself can be quite advanced one (e.g. optimal control). Normally supervision is regarded as a meta-level activity with respect to control and is located in a higher level of hierarchical control and supervision system.
Similar to the case of control, supervision can be based on classical, mathematical models and be based on direct numerical processing of process signals, or may include signal-to-symbol transformation, symbolic information processing, knowledge engineering components and intelligent inference. Thus, roughly speaking, with respect to principal tools and approaches to information processing supervision can be divided into the two following groups of methods:
Classical supervision originates from classical automatic control theory, statistical methods and signal processing. Its strength follows from use of well-defined models and methods, precise calculations and currently available computational tools. Simultaneously, it encounters difficulties when approaching non-numerical data, large amounts of data (e.g. data overload), in situations when precise mathematical models are unknown, unavailable or too complex, and when mathematical methods are irrelevant. Further, in some cases man-machine communication becomes difficult, since human experts typically reason at the symbolic level.Classical supervision, based on numerical signal processing, and Intelligent or Knowledge-Based Supervision, which makes use of symbolic knowledge representation and inference.
Knowledge-based supervision, on the other hand, deals with symbolic knowledge considered as principal input, output and system component. Its roots can be traced to domains such as Artificial Intelligence (AI), especially Knowledge Engineering (KE), logic and various branches of computer science; of course, substantial background comes from automatic control domain, especially digital control and automata theory. Some other links can be traced to computational linguistics, database theory and practice, algebraic methods, etc. The basic input for a knowledge supervision system consists of symbolic data. Such data can be observed directly from the process or generated as the output of numerical signal transformation to symbolic form. Knowledge processing takes the form of one or several modes of automated inference. The output of such systems is typically presented in symbolic (or graphical) form, easy to understand by process operators. A number of symbolic inference mechanisms can be used to support information processing, some most important form the point of view of application in supervision will be described later on in this work. Knowledge-based supervision is also named intelligent supervision, since information processing methods are based on operationally similar processes typical for human beings.
1.1.2 Knowledge-based supervision: a bit of history and current problems
Probably the first noticeable paper putting forward the idea of application of Artificial Intelligence (AI) methods to intelligent process control was the one by Fu [Fu, 1971]. Around and after that time theoretical papers and some laboratory works, especially in the domains such as planning became more widely propagated.
One of the first applied systems described in the literature was the
Ventilator Manager (VM) described in details in
[Fagan, 1980]. VM was an on-line
real-time system developed for interpretation of physiological data in
an intensive care unit. An automatic monitoring system was used to provide
VM with the values of 30 physioloogical data at 2 and 10 minutes sampling
rates. The data was then used to support management of post-surgical patients
receiving mechanical ventilatory assistance. IT work consisted in mechanical
inference applied for establishing guidelines for patient measurements,
including dynamical definition of upper and lower limits for comparison
with new measurements. The output of VM consisted of suggestions to clinicians
and generation of periodic report summaries. The techniques applied included
forward chaining, checking if temporal information (formerly acquired)
is still valid, and rule interpretation cycle mechanism.
In the eighties, a number of supervisory systems, supporting or including knowledge-based control and decision making were developed. A good review of the considered problems and applications is given in [Laffey et al, 1988]. The discussed applications include aerospace industry applications, communication, medical systems, process control, and robotic systems. Further, tools and techniques used are briefly outlined. One of the theoretical issues of the paper consisted in definition and discussion of relatively new problems concerning real-time knowledge-based systems, contrasting these applications from classical expert systems operating on static knowledge. The provided there list include the following issues:
Each of the above issues constitute a specific problem to be solved. Further, one must take into account the complexity following from large, complex, and often incompletely specified models, large numbers of input signals (e.g. 500 analog and 2500 digital on an oil rig platform, but up to 20,000 may be considered as well), and required response times (e.g. 100 milliseconds in some time-critical pilot associate program). Another example can consists the problems of excessive data: imagine monitoring a turbine rotating with the speed of up to 30,000 rotations per second. imagine that the task consists in real-time monitoring of only four sensors measuring the displacement, each of them four times per rotation. This gives as much as 8,000 measurements per second. Now, if the A/C conversion uses 8 bit base, this gives around 8kB of data per second, and around 28 MB per hour, and finally 0,7 GB per 24 hours of observation. If the information is not pre-selected, compressed and processed on-line to obtain more concise, semantic or qualitative data, than storage and management becomes a serious problem. Obviously, human interpretation can hardly be considered to be realistic.nonmonotonicity (temporal knowledge), continuous operation (e.g. garbage collection problems), asynchronous events (interruptions, reactivity), interface to external environment, uncertain and missing data, high performance, temporal reasoning, focus of attention, guaranteed response time, integration with procedural components.
Development and applications of knowledge-based systems and methods
in process monitoring, supervision, control, diagnosis, and decision support
constitute nowadays a very vast area of knowledge. Currently, it would
be hard to point to a single position covering or even pointing to mayor
issues, approaches and results. Some available positions include, but are
not limited to, [McGhee et al,
1990], [Rakoto and Aguilar,
1995], [Stock 1989], [Tzafestas,
1987], [Tzafestas, 1989] and
[Tzafestas, 1989a].
Obviously, control, supervision and diagnosis is performed to obtain certain results: the basic one being the final product or output (solution, decision) with required quantity and quality. Further problems may also include limiting human effort, environment protection, cost minimization, optimal efficiency, etc. In fact, quality of the process and product seems to be a factor attracting most attention now. But what is the quality, then?
In order to be more precise, quality must be defined in terms of possible to evaluate characteristics, conditions to be satisfied, or comparative criteria. Several approaches are possible: unique numerical or symbolic quality index (or indices), multiple-attribute characteristics, specification of minimal requirements, ordering (linear or partial), etc. Only after introducing a way of quality evaluation we may speak about possibilities of quality improvement.
In order to do so, factors influencing quality should be identified, and their influence on the quality indices must de learned or determined with use of models. Further, the scope of possible modifications must be specified and limiting constraints have to be provided. Only then one can search for improvement.
In order to perform the above procedure, certain tools should be available.
These tools include, but are not limited to, general systems and domain
specific terminology, languages -- formalisms for data and knowledge representation,
models, data and knowledge processing tools and evaluation procedures.
Presentation and discussion of selected of these issues is a principal
matter of interest of this work.
![]()